
Photo by Sung Wang on Unsplash,本文来自微信民众号:机械之心(ID:almosthuman2014),由机械之心整顿
昨天,第 N 次在公共场所 diss 激光雷达的马斯克,再一次让自动驾驶圈对无人车分歧的传感器运用计划展开了热议。
实际上,若是站在马斯克的角度,我们实在不难理解他对激光雷达的“怅恨心思”。
终究效果特斯拉是一家面向一般消费者卖车的企业,而不是一家卖自动驾驶手艺和解决计划的公司。
在最少 3 年内,无论是从本钱、手艺牢靠性、平安性、雅观性以至是用户对自动驾驶的信托度和品尝来看,大多数车企的量产车型,都不会把激光雷达归入斟酌领域。
固然,依据马斯克措辞常常打脸的典范显现来看,也许在几年后他会本身站出来辩驳本身对峙的看法。
事实上,在“自动驾驶汽车终究应当用不用激光雷达”这个问题上长时间的争论不休,衍生出了“激光雷达派”与“纯计算机视觉派”。
现在,一个被激光雷达派和群众广泛接收的看法是,斟酌到纯视觉算法在数据情势和精度上的缺乏,L3 级以上的自动驾驶乘用车必需要接纳激光雷达。
固然,从谷歌 Waymo、通用 Cruise,再到百度阿波罗和国内的 Pony.ai、文远知行等自称 L4 级自动驾驶乘用车解决计划的公司,车顶上的激光雷达一向都异常刺眼。
而“计算机视觉派”的重要组成局部则是自动驾驶手艺解决计划始创公司,但这个解决计划终究是多高的级别,实在现在没有确实的定论。
通常情况下,“高贵的本钱”和“手艺才能”是浩瀚车企与计算机视觉手艺公司阻挡接纳激光雷达的重要来由。
比如作为一家主打摄像头计划的手艺创业公司,2017 年 AutoX 的“炫技首秀”就是让一辆只搭载 7 个摄像头的林肯 MKZ 跑在一般公路的车道上。虽然厥后受到了来自激光雷达派的“回击”,其创始人兼 CEO 肖健雄也一向对峙以摄像头为主的传感器计划,
另外,局部高精舆图创业公司也强调从本钱动身,接纳低本钱的摄像头计划收罗高精数据。
综合来看,停止现在自动驾驶圈内最主流的看法虽然是“该有的,一个都不能少”,但不难看出,做车厂的买卖,关于计算机视觉公司来讲,暂时性抛开激光雷达是个还不错的主张;
而另外一层面,关于计算机视觉工程师来讲,想要在高级别自动驾驶解决计划上挣脱激光雷达,就要延续研讨和考证纯视觉手艺计划替换激光雷达的可行性。
因而,当人人还在围观“马斯克骂激光雷达”时,我们想从机械之心善于的角度动身,看看可否从手艺上来“考证”这个看似不太靠谱的看法。
很恰巧,我们发明了一篇来自康奈尔大学的手艺论文,作者中 Yan Wang 与 Wei-Lun Chao 均为华人。该论文提出了一种新要领来收缩纯视觉手艺架构与激光雷达间的机能差别。
该论文提出的要领,转变了平面摄像机目的检测体系的 3D 信息显现情势,以至将其称之为——伪激光雷达数据(pseudo-LiDAR)。
研讨者在挡风玻璃两侧各运用一个相对低价的摄像机,接纳其新要领以后,该摄像机在目的检测方面的机能靠近激光雷达,且其本钱仅为后者的一小局部。研讨者发明以俯瞰图而不是正视图来剖析摄像机捕捉到的图象可以或许将目的检测正确率提拔 2 倍,从而使平面摄像机成为激光雷达的可行替换计划,且其本钱比拟后者要低许多。
研讨主题
牢靠和妥当的 3D 目的检测是自动驾驶体系的基本请求。要想避免与行人、骑自行车的人、汽车相撞,自动驾驶汽车必需第一时间检测出它们。
现有的算法严峻依靠激光雷达(LiDAR),它可以或许供应周边环境的正确 3D 点云。只管激光雷达的正确率很高,但出于以下缘由,自动驾驶行业急需激光雷达的替换品:
起首,激光雷达异常高贵,给自动驾驶硬件增添了大批用度;
其次,过分依靠单个传感器会带来平安风险,在一个传感器涌现毛病时应用备用传感器是较优的挑选。一个天然的挑选是来自平面摄像机或单目摄像机的图象。光学相机性价对照高(比激光雷达廉价了多个数量级),且可以或许高帧率运转,可以或许供应浓密深度图,而激光雷达旌旗灯号只要 64 个或 128 个希罕扭转激光束。
近期的多项研讨探究了在 3D 目的检测中运用单目摄像机和平面深度(视差)预计 [19, 13, 32]。然则,现在重要的效果仍然是激光雷达要领的增补。
比方,KITTI 基准上的一个顶尖算法 [17] 运用传感器融会(sensor fusion)将汽车的 3D 均匀精度(AP)从激光雷达的 66% 提拔到了激光雷达+单目图象的 73%。而在仅运用图象的算法中,以后最优算法的 AP 仅为 10% [30]。
对后者较差机能的一个直观且盛行的诠释是基于图象的深度预计正确率较低。
与激光雷达相反,平面深度预计的偏差跟着深度增添而显现二阶增进。然则,对激光雷达和平面深度预计器天生的 3D 点云举行视觉对照后发明,这两种数据模态之间存在高质量的婚配,以至远处的物体也是云云(详见图 1)。

图 1:来自视觉深度预计的伪激光雷达(pseudo-LiDAR)旌旗灯号。左上:KITTI 街景图象,个中汽车四周的赤色界限框是经由过程激光雷达猎取的,而绿色界限框是经由过程伪激光雷达猎取的。左下:预计到的视差图。右:伪激光雷达(蓝色)vs 激光雷达(黄色)。个中伪激光雷达点与激光雷达的点很好地对齐。
解决计划
这篇论文供应了另外一种诠释——研讨者假定平面摄像机和激光雷达之间机能差其他重要缘由不在于深度正确率的差别,而是在于在平面摄像机上运转的 ConvNet 3D 目的检测体系的 3D 信息透露表现。
具体来讲,激光雷达旌旗灯号通常被透露表现为 3D 点云或许“俯瞰”视角图,并据此举行处置惩罚。在这两种情况下,目的的外形和巨细都不会跟着深度而发生变化。
而基于图象的深度预计重如果针对每一个像素,通常被透露表现为分外的图象通道,使得远处的工具很小,不容易被检测到。更蹩脚的是,这类透露表现的像素近邻将 3D 空间中较远地区的点群集在一起,这就使得在这些通道上实行 2D 卷积的卷积收集更难推理,和正确地定位 3D 空间中的物体。
为了考证这一结论,该研讨引入了一种适用于平面摄像机 3D 目的检测的两步法。起首将来自平面摄像机或单目摄像机的预计深度图转换为 3D 点云,即模仿激光雷达旌旗灯号的伪激光雷达;然后应用现有的基于激光雷达的 3D 目的检测流程 [23, 16],直接在伪激光雷达透露表现上举行练习。
经由过程转变伪激光雷达的 3D 深度透露表现,使基于图象的 3D 目的检测算法取得亘古未有的正确率提拔。具体来讲,在 KITTI 基准上取得 0.7 交并比(IoU)的汽车实例在考证集上取得了 37.9% 的 3D AP,比之前最优图象要领的正确率提拔了 2 倍。如许就可以把基于平面摄像机和基于激光雷达的体系之间的差别减半。

图 2:用于 3D 目的检测的两步 pipeline。给定平面或单目摄像机图象,研讨者起首展望深度图,然后将其转换为激光雷达坐标体系中的 3D 点云,即伪激光雷达。然后像处置惩罚激光雷达一样处置惩罚它,因而任何基于激光雷达的 3D 检测算法都能在其上运用。
研讨者对平面深度预计和 3D 目的检测算法的多种组合举行了评价,并获得了异常一致的效果。这表明机能的提拔是由于运用了伪激光雷达透露表现,它较少依靠于 3D 目的检测架构的立异或深度预计手艺。
总之,该论文有以下孝敬:
-
起首,经由过程实考证实,基于平面摄像机和基于激光雷达的 3D 目的检测手艺之间的机能差别不是由于预计深度的质量,而是由于透露表现。
-
其次,研讨者提出了一种新型 3D 目的检测预计深度透露表现——伪激光雷达,将之前的最优机能提拔了 2 倍,到达了以后最好程度。
-
这一研讨效果表明,在自动驾驶汽车中运用平面摄像头是能够的,如许既可以或许极大地降低本钱,又可以或许革新平安机能。
论文:Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving

论文链接:https://arxiv.org/abs/1812.07179
择要:3D 目的检测是自动驾驶的一项重要任务。若是 3D 输入数据是经由过程准确但高贵的激光雷达取得的,那末现在的手艺可以或许取得高度准确的检测率。基于较廉价的单目摄像机或平面摄像机图象数据的要领现在可以或许到达的正确率较低,这类差别通常被归因于基于图象的深度预计手艺缺点。
但是,在本文中,研讨者以为,数据透露表现(而非其质量)是形成这类差其他重要缘由。研讨者将卷积神经收集的内部事情道理斟酌在内,提出将基于图象的深度图转换为伪激光雷达透露表现——本质上是模仿激光雷达旌旗灯号。有了这类透露表现,我们就可以运用当下基于激光雷达的种种分歧检测算法。
在盛行的 KITTI 基准上,该论文提出的要领在基于图象的机能方面取得了使人印象深入的革新,逾越以后最好要领,将 30 米范围内的目的检测正确率从以后最好的 22% 进步到了 74%。停止论文提交时,该论文提出的算法在基于平面图象要领的 KITTI 3D 目的检测排行榜上到达了以后最高程度。
试验
研讨者经由过程分歧的深度预计和目的检测算法,在分歧的设置下评价了有/没有伪激光雷达的情况下 3D 目的检测的效果(如下表)。伪激光雷达获得的效果显现为蓝色,实在激光雷达的效果显现为灰色。
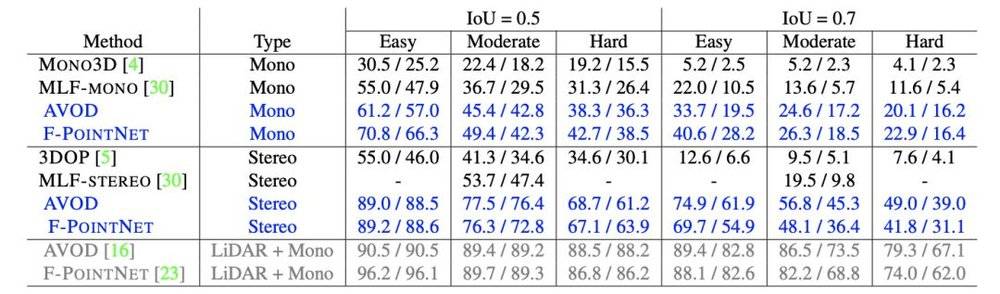
表 1:3D 目的检测效果。表中显现了汽车分类的 AP_BEV / AP_3D 百分率、对应于俯瞰图和 3D 目的框检测的均匀精度。
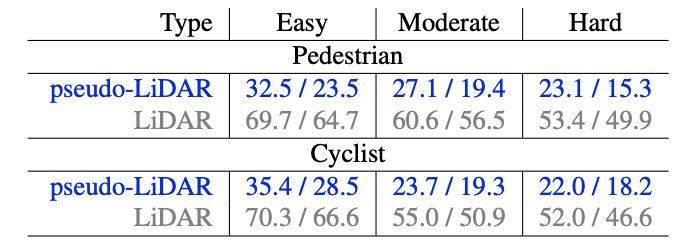
表 4:行人和骑车人类其他 3D 目的检测效果。研讨者报告了 IoU = 0.5(范例器量)时的 AP_BEV / AP_3D,并将 PSMNET(蓝色)预计的伪激光雷达和激光雷达(灰色)举行对照,两者都运用 F-POINTNET 算法。

图 4:定性对照。研讨者运用 AVOD 算法对激光雷达、伪激光雷达和正视图(平面)举行了对照。赤色框中的是 Groundtruth,绿色框中的是展望框;伪激光雷达图象(下面一行)中的观察者在最左侧向右看。正视图要领(右)以至错误计算了左近目的的深度,而且完整无视了远处的目的。
参考链接:
https://arxiv.org/abs/1812.07179
https://www.sciencedaily.com/releases/2019/04/190423145508.htm
本文来自微信民众号:机械之心(ID:almosthuman2014),由机械之心整顿
*文章为作者自力看法,不代表虎嗅网态度
本文由 机械之心 受权 虎嗅网 宣布,并经虎嗅网编纂。转载此文请于文首标明作者姓名,连结文章完整性(包孕虎嗅注及其他作者身份信息),并请附上出处(虎嗅网)及本页链接。原文链接:https://www.huxiu.com/article/296010.html
未依照范例转载者,虎嗅保存追查响应义务的权益
将来眼前,你我还都是孩子,还不去下载 虎嗅App 猛嗅立异!,返回网站首页
关注我们:请关注一下我们的微信公众号:扫描二维码
 ,公众号:aiboke112
,公众号:aiboke112版权声明:本文为原创文章,版权归 所有,欢迎分享本文,转载请保留出处!



评论已关闭!